

Vi è mai capitato di andare a cercare una notizia che avevate letto poco tempo fa, e scoprire con sorpresa che quella pagina web non esiste più? A volte succede, ed è una vera seccatura, e non c’è servizio di lettura asincrona che tenga (come Pocket, per dirne uno). Per questo motivo ha senso ottenere delle copie delle pagine che vi interessano, magari con metodi un po’ antiquati. Vediamone un paio.
Salvare pagine web: fare il download da soli
Iniziamo proprio dalle basi: potete salvare le pagine che state leggendo dal vostro browser, utilizzando i comandi dei diversi browser: tendenzialmente salverete una pagina HTML, ma non è detto che otterrete anche tutte le risorse di quella pagina, come le immagini o i fogli di stile. Allo stesso modo stampare un pdf della pagina: se vi interessano i dati puri, potrebbe bastarvi.
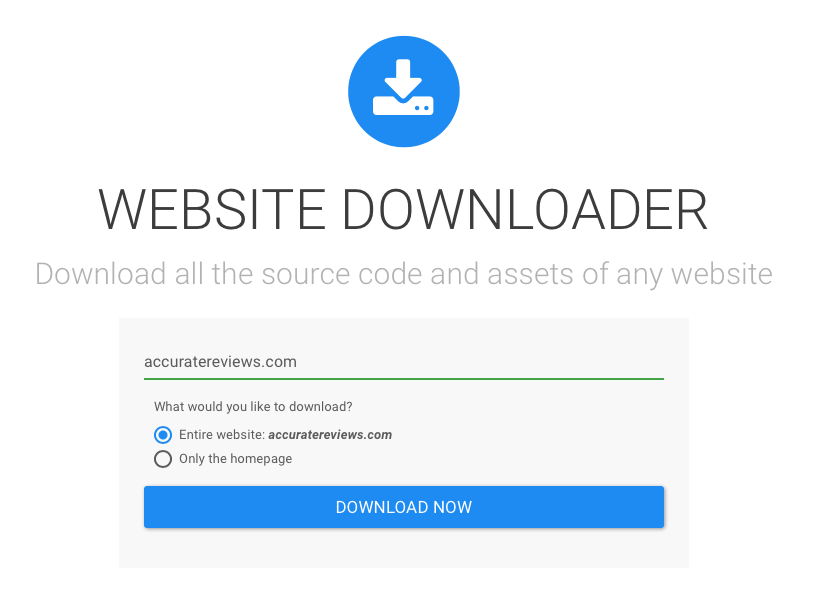
Salvare pagine web: utilizzare software o servizi terze parti
Abbiamo già parlato di Website Downlaoder, il servizio che gratuitamente una prima volta, a pagamento dalle volte successive vi permette di scaricare tutto – o quasi – ciò che forma un sito web. Ci sono altri modi per ottenere lo stesso risultato, ovviamente: per esempio potreste utilizzare Archive.is, che oltre a salvare le url che gli sottoponete in un archivio .zip ne cattura uno screenshot.
Salvare pagine web: usare Wayback Machine
Abbiamo anche già parlato della bellissima macchina del tempo di Internet Archive, che analizza i siti web a intervalli irregolari e ne ottiene una copia in quel momento (e salvandone anche gli asset). Più un sito è importante e famoso, più spesso Wayback Machine tornerà a fare una scansione.
Salvare pagine web: usare software di screen capture
Ci sono alcune estensioni per browser che permettono di effettuare uno screenshot, per esempio Save to Google Drive (se siete utenti Drive), oppure Skitch, un’app di Evernote che permette di fare schizzi, annotazioni, ma anche salvare screenshot.